understanding ZeRO!
starting with a single number
forget everything that you know. forget model. forget parameters. let's just start with a single number. a neural network is just a floating point number - say 0.347. so now if we say we have a billion parameter model what we are trying to say is that we have billion of these "0.347" sitting in memory. now the question arises, how much of space do these billion numbers occupy. well that depends on how these are getting stored. if we store them in fp32 format they will occupy 4 bytes, if in fp16 or bf16, then they will take 2 bytes.
what happens to this number during training?
so training is not just about storing our 0.347 in memory. it is more than that. basically there are three operations that take place.
- forward pass - uses the weight to compute a prediction
- backward pass - compute how wrong our prediction was
- optimizer step - use the gradient to update the weight so that the loss decreases
let us say our weights (w) = 0.347. after we do a backward pass we find out that the gradient (g) = 0.021, meaning we need to change our weight, it needs some update. for this update we use the Adam optimizer (in this example). but the thing is Adam optimizer doesn't do w = w - 0.021. It is actually smarter. if we go deep into it we understand that it store 2 values for a single parameter.
- momentum (running average of gradients)
- variance (running average of gradients^2)
so for every single weight Adam has to store three numbers : g,m and v. also these numbers are required to tune the weights and since these updates can be very precise , Adam stores them in fp32 (4 bytes each) even if the weigth is stored in fp16 (2 bytes) in memory. on top of it we store "fp32 master weight" alongside out fp16/bf16 weight. this is due to the same reason as above - "precision". Adam computes the update w_new = w - lr × m / (√v + ε) and the result can be a very small number which if applied to a weight store in bf16 format cannot do anything as it will be rounded off due to low precision thus making the update lost.
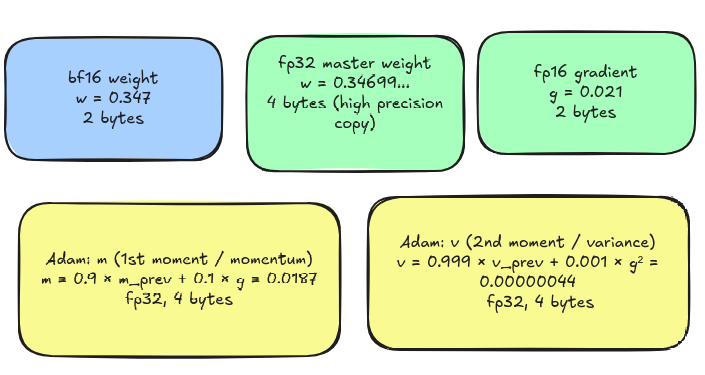
so for just 1 weight we are using 16 bytes of memory
now let us move to multiple GPUs
let us say we have very tiny model with 4 weights and we have 4 GPUs. y main goal is to train faster with the help of utilising all of these GPUs.
standard DDP
each GPU gets a different piece/slice of training data (different sentences/images etc) but the thing is each GPU stores the entire model. so by model we mean all the weights, gradients, momentum and variance.
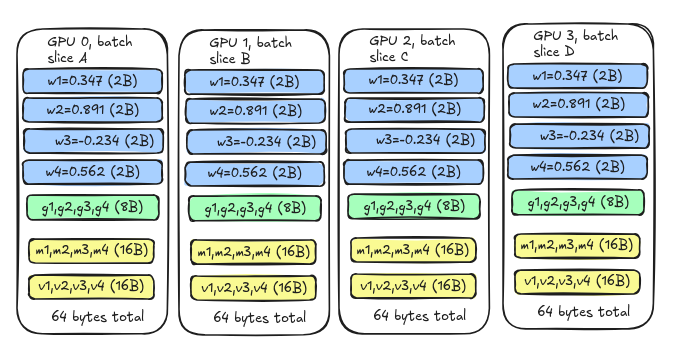
the waste counted: the system is using 4 x 64 = 256 bytes total but if we see that only the first copy (64 bytes) is useful - rest is just getting repeated. there are 3 identical copies of m and v that are useless. adding more GPUs will just result in us getting more of these stupid extra copies. here comes in ZeRO. its entire mission is to eliminate these waste copies.
ZeRO Stage 1
the idea is simple - each GPU will be assigned a responsibility of specific weights. GPU0 will own w1, GPU1 will own w2 and so on. because of this each of the GPU will need to run the Adam update on the weights its responsible for thus storing Adam weights for its slice of weights.
pipeline:
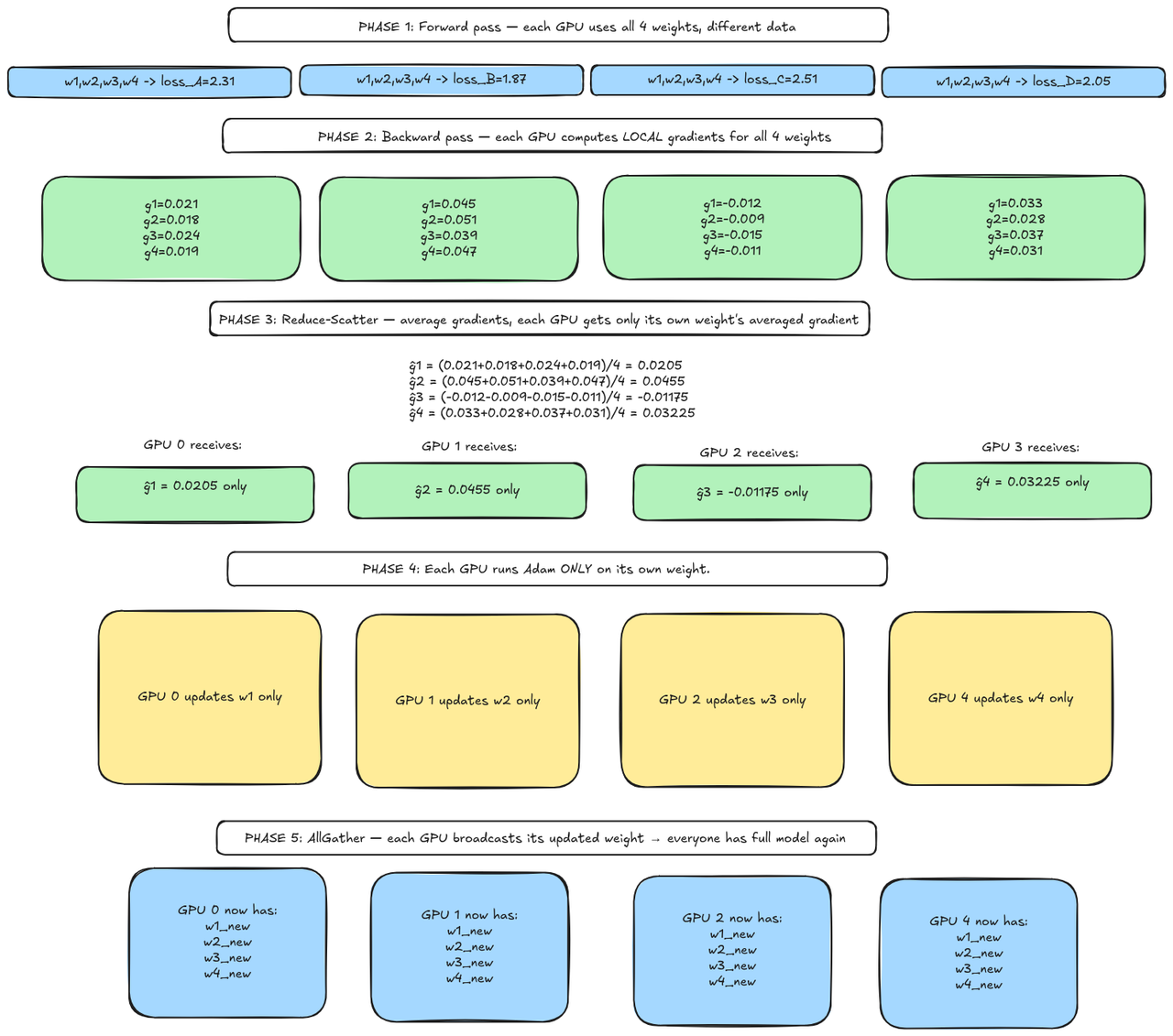
let us count the memory usage:
DDP : each GPU stores w1,w2,w3,w4 (8B) + g1,g2,g3,g4 (8B) + m1,m2,m3,m4 (16B) + v1,v2,v3,v4 (16B) , total = 48 bytes
ZeRO-1 : Each GPU stores w1,w2,w3,w4 (8B) + g1,g2,g3,g4 (8B) + only its 1 m (4B) + only its 1 v (4B) = 24 bytes
Half the memory. Exactly. With 4 GPUs, optimizer states went from 32 bytes per GPU down to 8 bytes per GPU.
ZeRO-2:

look at this. if we observe here we can see that we are initially storing all the gradients in the GPU. but we know that each GPU has the responsibility of a specific weight right? GPU0 updated the w1 and for that it needed just g1^. here comes in ZeRO-2 which states that as soon as the backward pass computes a gradient we immediately reduce-scatter it : so GPU0 accumulates only the average g1^ and discards everything else. the gradients for the other weights never get assembled on GPU0.
ZeRO-3:
now see, both stages 1 and 2 keep all 4 weghts on GPU which is still redundant. since we know that ultimately a single GPU owns a weight and is responsible for updating that specific weight only , ZeRO 3 states that " each GPU permanently owns only its slice of the weights too". so GPU0 will own w1, GPU1 will own w2 and so on. but again there is a problem here. for our forward pass we need all the weights to be present on the GPU so that we can make predictions right. so for that we need to temporarily borrow them.
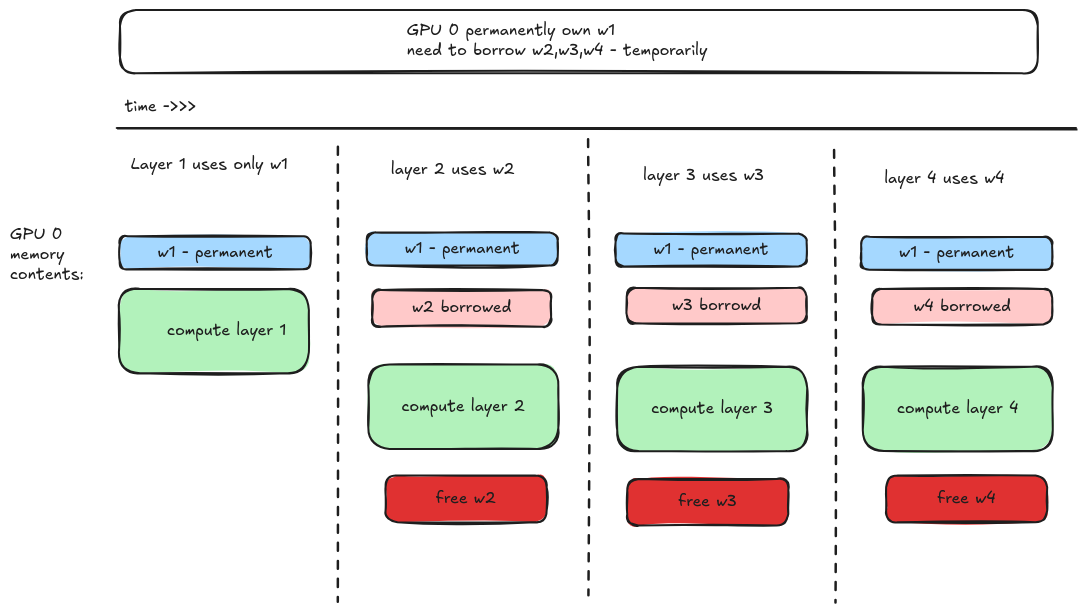
how much memory did we save?
DDP : 4 weights x 2B = 8B params per GPU (always) ZeRO-3 : 1 weight x 2B = 2B params/GPU (permanently) + 1 weight x 2B = 2B (temporarily during compute)
Peak : 4B - which is half of DDP
how does communication really happen?
when we say GPU 0 sends data to GPU 1 we make it look simple but it is very complicated.
the physical hardware layer
GPUs are interconnected through interconnects and these interconnects determine bandwidth - the number of bytes that can flow per second.
within a single node (one machine with 8 GPUs):
NVLink. this is NVIDIA's proprietary high-speed direct GPU-to-GPU connection. on H100s, NVLink 4.0 gives 900 GB/s total bidirectional bandwidth. this is fast enough that sending the parameters of an entire 7B model takes about 15 milliseconds. NVLink forms a mesh or switch topology — every GPU can talk to every other GPU simultaneously without going through the CPU or system memory.
across nodes (multiple machines): InfiniBand or Ethernet. InfiniBand HDR gives around 200 Gb/s per port, which is roughly 25 GB/s. that is 36× slower than NVLink. This is why multi-node training is communication-bound in a way that single-node is not. The software tries desperately to overlap computation with this slower cross-node communication.
software layer: NCCL
you never directly send or receive in pytorch. instead we use this library NCCL (NVIDIA Collective Communications Library). it provides us with collective operations - where all GPUs participate together with a defined contract about what each one sends and receives.
when PyTorchFSDP or DeepSpeed wants to do an AlLGather it calls nccAllGather(). NCCL then figures out the optimal ring, tree, or recursive halving algorithm for your specific topology, launches CUDA kernels on the GPU to do the actual data movement, and handles all the synchronization. your training code just sees a function call that blocks until everyone has the result. also NCLL runs entirely on GPU so there is 0 data movement through the CPU RAM.
AllGather in practice
say we have 4 GPUs and each 1 GB of shard parameters and we want to do all AllGather so that each of the GPU has all 4GB parameters. NCLL implements a ring algorithm and it arranges the 4 GPUs in a ring.
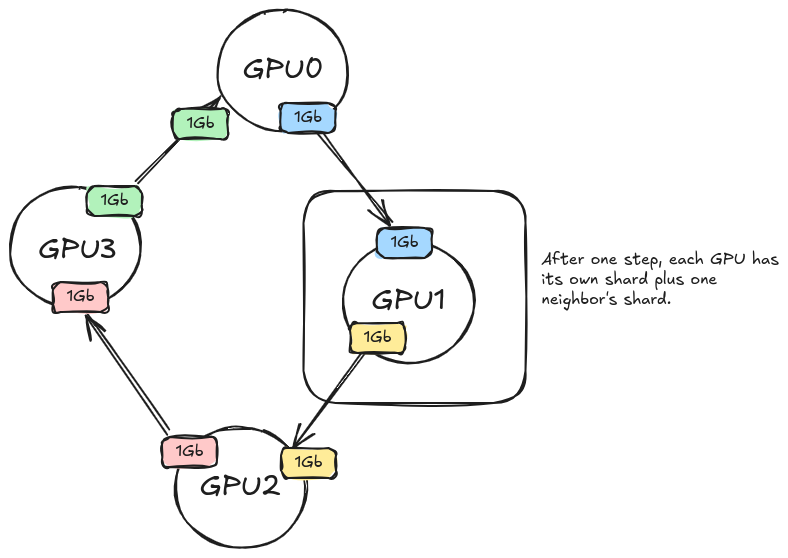
in the first step GPU0 sends its 1GB shard to GPU1 while simultaneously GPU1 sends its shard to GPU2. this takes places for all the GPUs and as you can see in the diagram at each step has its own shard + its neighbour's shard.
After 3 steps (N-1 steps for N GPUs), everyone has all 4 shards. Total data sent per GPU: 3 GB. Total received per GPU: 3 GB. This is why the AllGather cost formula is M × (N-1)/N ≈ M for large N — each GPU sends its own M/N shard N-1 times, totalling (M/N) × (N-1) = M(N-1)/N bytes sent.